
The Seed and the Harvest

At a recent AI convening, two things that struck me had almost nothing to do with AI.
Early on, Murugan from Veddis Foundation spoke about Kunji, a Glific-based WhatsApp bot used by government officials to access policy-related information. In a Q&A following his talk, it became clear that for this approach to work (or be scaled up) one first has to streamline and structure all the policy-related documentation, which could be spread across multiple departments. This consolidated set of documents is then used to train the bot. So building the bot is the easy part – the hard bit is the cleanup needed upfront, which also includes setting up processes to keep this document repository updated. All this is just good practice, which can yield benefits even without AI. And without this preparation, even the best intelligence is of little use.
Knowledge management at the workplace has a similar constraint. Gemini is good at summarizing files and folders on Google Drives. This can save a lot of time (and yield interesting insights) while scanning a large number of documents from historical projects. But Gemini is of limited use if, as an organisation, you haven’t structured your shared drives and set up a process to save project-related work on those folders (not on an individual’s “My Drive”). That initial part is time-consuming and messy. At Sattva, where I work, it took many months of a company-wide “Shared Drive” initiative to get this done. And now, in the context of AI, this matter needs to be revisited. We are considering how to restructure parts of our shared drives (and fine-tune some processes) to enable Sattva employees access – via a bot – the vast trove of knowledge hidden in these drives.
Later in the day, Jerome from Project Tech4Dev, spoke about the tendency of nonprofits to build bespoke AI applications from scratch, and the need to rethink this approach. He presented Tech4Dev’s AI platform as an example of how common functionalities – like authentication, document management, etc – can be abstracted within a common platform, saving time and effort for every application to build and maintain these features. This is just good engineering practice, nothing to do with AI in particular. But given the rapidly growing landscape of AI apps and solutions, it is timely advice.
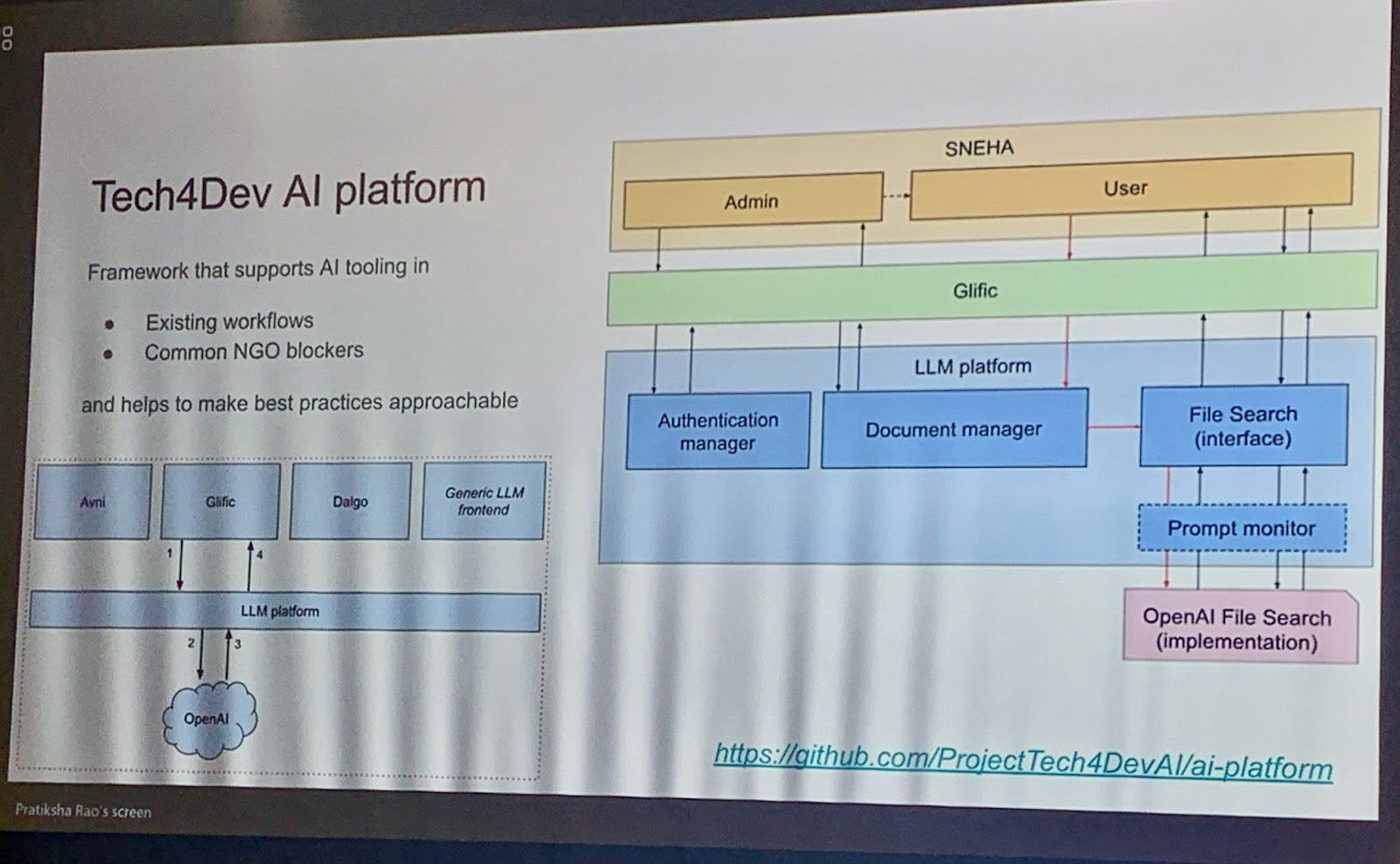
Jerome’s talk reminded me of the years that followed the iPhone launch, when software firms began to create an app for every conceivable use-case. At one point, the HR function of the enterprise software company I worked for had developed half a dozen apps. Each one from a different team, driven by Conway’s law. All this unregulated enthusiasm for a cool new piece of technology led to frustration among our customers, who had to switch often between apps for a single workflow, or deal with different UI approaches for the same problem. It took a few years for sanity to be restored.
The talks at the event highlighted GenAI’s potential and pitfalls, and the use-cases presented gave a glimpse of its social impact. I left the event with a sense of deja vu. Some things did not change: without data hygiene you couldn’t go too far, without reusable infrastructure you’d end up with waste, and ignoring the consumer landscape can lead to a messy riot of overlapping solutions. In the middle of this AI revolution, it’s good to consider what’s needed before, and keep an eye on what will come after.